
Resizing AWS root EBS in CentOS HVM
Update 04.07.15
This method doesn’t work anymore because of some weird AWS restriction, which says you can’t connect the root device of a marketplace AMI (like the CentOS one) to another VM, lest you discover its secrets.
I developed a better method which involves either rebooting or creating a custom AMI. Give it a try!
The Story
Today I started using HVM instances in AWS, because r3 instances (memory optimized) are only available on HVM (the difference). Because the CentOS image my company uses isn’t available as HVM, I switched to this image, which had an annoying side effect.
The Problem
After launching an instance, I always extend the root volume, which starts at a measly 8GB. Linux runs fine on 8GB, but our devs depend on some maneuvering space.
The EBS volume itself is extended when launching the instance. However, one must also extend the partitions/filesystems inside the volume.
Our previous image provided a root EBS that contained the filesystem directly, like this:
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
...
xvde 202:64 0 100G 0 disk /
...
Here we only have to extend the filesystem, which can be done using something like:
resize2fs $(mount | perl -ne 'print $1,"\n" if /^(\S+) on \/ /')
On the HVM image, however, the EBS was partitioned (using MBR) and had a single partition, which contained the filesystem, like this:
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
...
xvda 202:0 0 100G 0 disk
└─xvda1 202:1 0 100G 0 part /
...
This means that we must extend the partition before extending the filesystem, which proved to be a difficult task.
The standard procedure is deleting the partition and recreating with the same settings, however:
- Since we’re extending a partition which contains the root filesystem, we can’t unmount it.
- When changing a partition that contains a filesystem that is mounted, the kernel refuses to re-read the filesystem, meaning you can’t make sure everything works until you reboot
- If you’re rebooting with a broken partition/filesystem configuration, the VM won’t boot. Since AWS offers no direct method of interfacing with the VM directly, one can’t easily troubleshoot the VM.
Because of this, I spent 6 hours and 6 servers on trying to extend the partition.
The Solution
As AWS say in their article, the best solution I found is using a helper VM.
- Prepare a helper VM running Linux, with
partedinstalled. - Stop both the instance you wish to extend and the helper.
- Note the instance id of both instances and the volume ID of the root EBS.
We’ll assume we’re talking about
i-victim,i-helper,v-victim - Note
i-victim’s root device configuration. We’ll assume it’s/dev/sda1

- Detach
v-victimfromi-victimand attach it toi-helper. The device letter doesn’t matter, you should be able to recognize it on the OS. We’ll assume it’s/dev/xvdf.
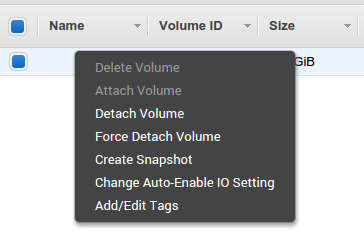
- Start
i-helper, connect to it via SSH, and commence surgery-
Use
parted /dev/xvdf pto view the current partition makeup, and save it in case something bad happens.:::text Model: Xen Virtual Block Device (xvd) Disk /dev/xvdf: 322GB Sector size (logical/physical): 512B/512B Partition Table: msdos Number Start End Size Type File system Flags 1 1049kB 8GB 8GB primary ext4 bootNote the difference between the drive size (
322GB) and the partition size (8GB) -
Like in the article, delete the partition and create a new one, with the same start and type. Put
100%as the end, and runset 1 boot onto enable the boot flag on the new partition .
Example code::::text $ sudo parted /dev/xvdf rm 1 $ sudo parted /dev/xvdf mkpart primary 1049kB 100% $ sudo parted /dev/xvdf set 1 boot onNote: The start (
1049kB) should be based on the start of the original partition.
The new partition should be recognized by the kernel, and the filesystem itself can be treated. - Execute
e2fsck -f /dev/xvdf1 && resize2fs /dev/xvdf1to fsck and extend the filesystem - You can mount-test the partition on the server, just to make sure everything is OK, using something like
mkdir /tmp/bla && mount /dev/xvdf1 /tmp/bla
-
- Stop
i-helper - Detach
v-victimfromi-helper - Attach
v-victimtoi-victim, using the binding from step 4.
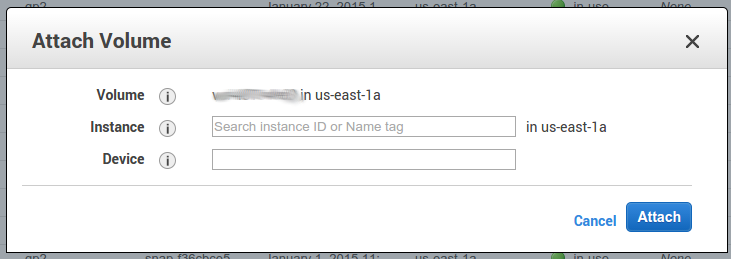
- Start
i-victimand pray.
Everything should work out OK