
Processing Israeli FOIA calendars, Part 1
Preface
I’m a volunteer in the Israeli Public Knowledge Workshop (wiki), which is a nonprofit working to increase transparency of Israeli’s ruling bodies (e.g. Goverment, Municipal authorities, courts).
I recently picked up a nice project that I thought would be worth a read.
Under the Israeli equivalent of FOIA (Freedom Of Information Act), citizens are able to request information form public authorities.
Some nonprofits are using this law to try and acquire calendars/diaries/journals of various public servants, and publish them to the public.
Aside from the obvious advantage in being able to ensure that a public servant spends their time in actually serving the public, there are instances where these calendars are useful in exposing conspiracies and hints of corruption (article in Hebrew).
We now have a lot of these calendars as individual files. We’d like to do some more advanced analytics on them, including cross-referencing them with one another, and for that we’d like to load them all up into a nice database.
This is my mission.
I called this project “Dear Diary”, as the Hebrew words for “Calendar” and “Diary” are identical.
Series Logistics
Instead of making a huge post, I’m going to divide it into a series to make it easier to read (and to write).
I’ll also try to make it readable for people who are not Linux / Python / whatever pros. Hopefully my family and friends will be able to read it and understand what I’m working on 😀
If you’re not a programmer, feel free to skip the code bits.
This is part 1
Data exploration and what we’re targeting
The first thing I wanted to do is to understand which data I’m dealing with. I went into the website that holds all of the FOIA-collected documents we have, and searched for “יומן” (Hebrew for “Calendar”). The URL looks like this:
https://www.odata.org.il/dataset?q=%D7%99%D7%95%D7%9E%D7%9F

Looks promising. I now tried to find an API equivalent, and it wasn’t that hard. Reading the docs and poking at some URLs gave me this:
https://www.odata.org.il/api/3/action/resource_search?query=name:יומן
You can try the url on your browser, and you’ll get a huge JSON object, detailing all of the files relating to calendars.
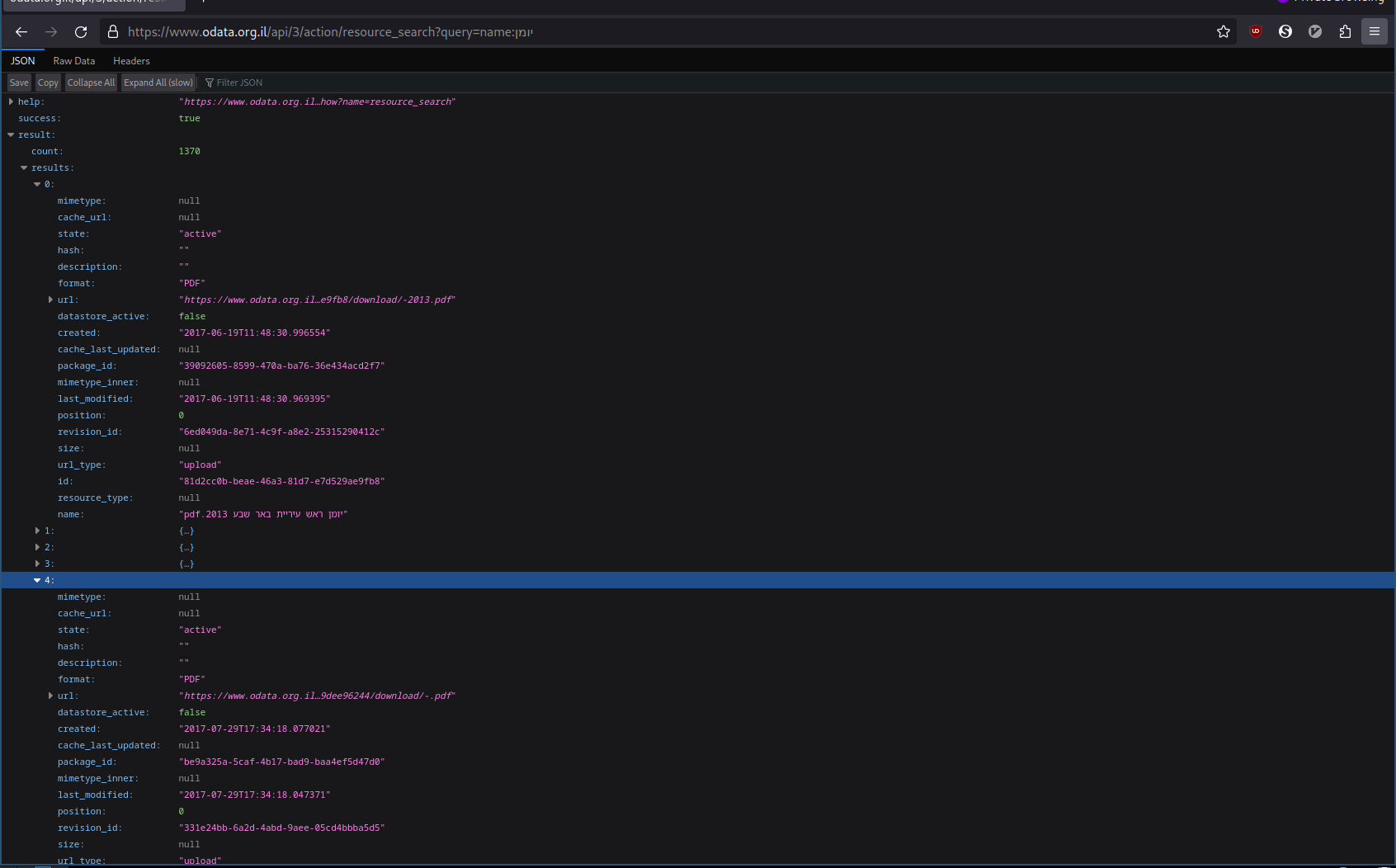
Using cURL (which fetches the list) and feeding the result to jq (which allows us to dive into the JSON), we can see what a single item looks like:
$ curl -s 'https://www.odata.org.il/api/3/action/resource_search?query=name:יומן' | jq '.result.results[0]'
{
"mimetype": null,
"cache_url": null,
"state": "active",
"hash": "",
"description": "",
"format": "PDF",
"url": "https://www.odata.org.il/dataset/39092605-8599-470a-ba76-36e434acd2f7/resource/81d2cc0b-beae-46a3-81d7-e7d529ae9fb8/download/-2013.pdf",
"datastore_active": false,
"created": "2017-06-19T11:48:30.996554",
"cache_last_updated": null,
"package_id": "39092605-8599-470a-ba76-36e434acd2f7",
"mimetype_inner": null,
"last_modified": "2017-06-19T11:48:30.969395",
"position": 0,
"revision_id": "6ed049da-8e71-4c9f-a8e2-25315290412c",
"size": null,
"url_type": "upload",
"id": "81d2cc0b-beae-46a3-81d7-e7d529ae9fb8",
"resource_type": null,
"name": "יומן ראש עיריית באר שבע 2013.pdf"
}
There are a lot of interesting fields, but for now we’ll look into “mimetype” (wiki), which is a web standard indicating of what kind of file this is.
Unfortunately, this file has “null” (meaning unknown), but most of the files don’t.
In order to see what we’re dealing with, we’re going to do a more complex command, that gets all the mimetypes and groups them, showing us the most common ones.
The command and result look like this:
$ curl -s 'https://www.odata.org.il/api/3/action/resource_search?query=name:יומן' | jq '.result.results[].mimetype' | sortiq | head
799 "application/pdf"
357 "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet"
78 "text/csv"
63 null
47 "application/vnd.ms-Excel"
9 "application/vnd.openxmlformats-officedocument.wordprocessingml.document"
6 "image/tiff"
4 "application/zip"
3 "text/calendar"
2 "application/vnd.openxmlformats-officedocument.spreadsheetml.template"
We can see that most of the files are in the PDF format, with “officedocument.spreadsheetml.sheet” (Excel 2007+ spreadsheets) in second place.
From manually looking at some of the PDF files, I saw that they’re hard to read.
Examples:
- this is a printed and scanned document, which is completly unintelligible for a machine without a lot of guesswork.

- this, while made of text, is nontrivial for a computer to understand.

Because the PDFs seemed to be problematic, I decided to start looking at Excel files as a first step.
Now that we know that we want the Excel files, we should download them locally so we can experiment on them.
For this, we’re going to get all of the files, filter out only the Excel ones, and download them all to a specific directory.
Let’s do this:
$ curl 'https://www.odata.org.il/api/3/action/resource_search?query=name:יומן' -s | jq '.result.results[] | select(.mimetype == "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet") | "mkdir -p output/reapings/\(.id) && curl -s \(.url) -o \"output/reapings/\(.id)/\(.name)\""' -r | parallel
The result in output/reapings is a bunch of directories, each one named after a file ID. inside, there are files:
$ ls output/reapings/ | head
00181757-0c0d-4f82-b389-b3624bdeec87
00caa5ea-f127-4da4-882b-0dd32e350a1d
012d05b8-6378-47f0-a0c2-ec0804a2b53e
018f36ba-5052-46be-8bd2-b5e29d2f83db
026b6b8e-43da-4c0b-8fcb-f75ae4f1acc0
05a626d9-8830-4d50-b514-f64fade06ab8
05d0a3fe-1f1b-4c7b-8977-65ad34a13939
0616d2bf-f8e3-4a09-ab77-ed13071ac9e9
06e244f5-4b9c-4f83-9166-75815d73dafa
07048613-e656-4229-935e-9f8522e49194
$ ls output/reapings/00181757-0c0d-4f82-b389-b3624bdeec87
'יומן מנכל העירייה 1.1.22-30.6.22.xlsx'
$ ls output/reapings/0616d2bf-f8e3-4a09-ab77-ed13071ac9e9
'יומן מרב מיכאלי.xlsx'
Let’s do a quick check of how many files we have:
$ find -type f | wc -l
2013
Let’s also ask how much space this directory takes:
$ du -hs output/reapings/
34M output/reapings/
So we now have 2013 Excel files, weighing 34 MegaBytes. Neat.
Next episode
Chewing, or how to take these Excel files and extract specific calendar events.