
Using a global lock in Chef
The Story
Our dev team is currently using a Snowflake-like ID generation scheme that looks like this:
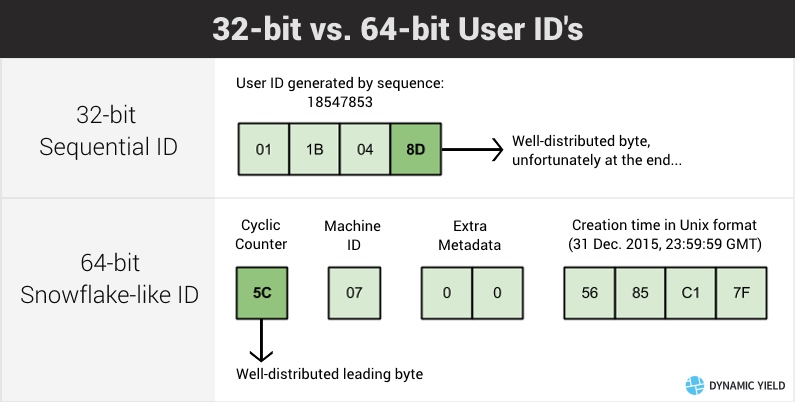
(Diagram by Elad Rosenhim, architect and companion at Dynamic Yield. See his post about distributed keys and how to survive managing an HBase cluster)
Those familiar with MongoDB might notice this structure is very similar to MongoDB’s ObjectId.
This ID generator has several advantages over sequential generation, mainly:
- Partitioning-friendly:
Because the most significant bits are rotated frequently, consecutive IDs will go to different partitions, avoiding a “hot-zone” problem. - Independent generation:
Every machine can generate IDs by itself, meaning there’s no single point of failure (as opposed to using MySQL sequences for ID generation) - Packed metadata:
The key allows including 4 bytes of arbitrary metadata (e.g. user’s country of origin), which can be later inferred from the key, in addition to the creation date. This metadata is “free” (not requiring an auxilary lookup).
The problematic bit for me is the need to assign a unique ID for every machine (to avoid machines creating duplicate keys).
As you can see from the diagram, I have 2 bytes allocated for this, which might seem like a lot (255 different machines), but this is not enough space to just put unique machine identifiers I already have (like FQDN, SSH fingerprint, EC2 instance ID).
I therefore needed to tell Chef to pick a machine ID that no other node has and use that.
Naively one could do something like this in a Chef recipe:
unless node['machine']['id'] then
range=(0..255).to_a # Total range allowed
# IDs in used, extracted using Chef search:
used_ids = search('machine_id:*',filter_result:{'id' => ['machine','id']}).
map{|node|node['id']}
available_ids = range - used_ids # Deduce remaining pool
raise 'No free ids' unless available_ids.any? # Upset if none
my_id = available_ids.first
node.normal['machine']['id'] = my_id # save it
end
However, several nodes could be running the same code at the same time, and since Chef offers no concurrency control, those nodes could get identical available_ids and choose the same my_id, leading to nodes with duplicate machine IDs, meaning they might create duplicate user IDs.
The solution
I initially thoguht about outsourcing the ID generation to a single-threaded HTTP application to eliminate any concurrency issues.
However, this application would have to hold all of the assigned IDs (as opposed to them being stored in the Chef server), and I find stateful applications much harder to maintain (backups, scaling etc).
Eventually, I thought about keeping the code inside a Chef recipe, but rely on an external service to ensure concurrency.
I found the RDLM (Restful Distributed Lock Manager) which is a simple global lock holder, where locks are acquired and released via HTTP requests, which was perfect for me.
To utilize the RDLM in Chef recipes, I built the lock_rdlm cookbook which includes several interesting functions.
The first is LockRDLM::with_lock, which executes a code block as a critical section, using a specified lock name.
One could use it to run a “critical” code section like this:
LockRDLM::with_lock(node,'lockname') do
# Code here will be exclusive
db = data_bag_item('misc','last_run')
db[node.name]=Time.now
db.save
end
The second is LockRDLM::assign_identity, which uses with_lock to look for identities of other machines and choose a different one (out of a range) for the current node.
It’s using the with_lock method internally, with the critical section doing the following:
- Iterates over all of the nodes in the Chef server and collects their values
- Chooses a free value for its own use
- Saves the value in the node object (for the current run).
- Loads this node’s object from the server, saves the value and immediately saves it back.
This is done to ensure that the newly chosen value is present in the server upon leaving the critical section, and not in the run’s end (when the Chef client updates the node object).
I use it to solve my use unique identity issue like this:
LockRDLM::assign_identity(node,[:machine,:id],(1..254).to_a)
# Now I can use node['machine']['id']
Interesting bits
- Because the identities are stored in Chef node attributes, they are cleaned up when node objects are removed. This is another benefit over having all of the ID assignment handled in a separate application.
- When creating the lock handling functions, I couldn’t rely on the Chef HTTP methods because they don’t return HTTP headers, which I needed. I had to fall back to
net/http, but it wasn’t so bad. - I found Dominodes that solves the same problem (critical sections accross nodes), but uses data bag items as the locks.
I didn’t take it becaue it doesn’t seem to handle race conditions. Also, it’s unmaintained since 2011, and I don’t think it’s because it’s perfect. - I use the helper function
LockRDLM::find_duplicate_identityto monitor for duplicates. One can use this function in their recipe to fail a Chef run if a duplicate is found - I prefer having servers with an assigned identity not depending on the lock during run and one server being in charge of looking for duplicates.